Technical Note
How to build Flexible Neural Networks from scratch in C++

Overview
This post basically describes how I built FlexNN. FlexNN is a fully connected neural network that can be customized to any use case by having any arbitrary number of layers, and support for multiple activation functions.
At the time of writing this article, FlexNN only has support for Dense layers and ReLU and SoftMax activation functions. Right now, I have no motivation to continue adding support for other types of layers and activation functions, since this project is intended just as a proof of concept and learning purposes. For any practical purposes I would shut up and pick TensorFlow without second thoughts.
What are we going to do
For designing a neural network we will first consider a problem statement to solve and a dataset for the same. So for this experiment, I've picked up the MNIST dataset for handwritten digit recognition.
The dataset contains a lot of 28x28 pixel images with handwritten digits from 0-9. In this, each pixel is an integer value from 0 to 255, with 0 representing black, and 255 representing white, and 50* shades of gray in between.
* more like 254 :)
Our model will basically look at a large subset of these samples, and learn how each digit looks like. And when we give it a random sample which it has never seen, it will try to pick up some patterns and guess which digit it is.
Okay what the hell is a neural network?
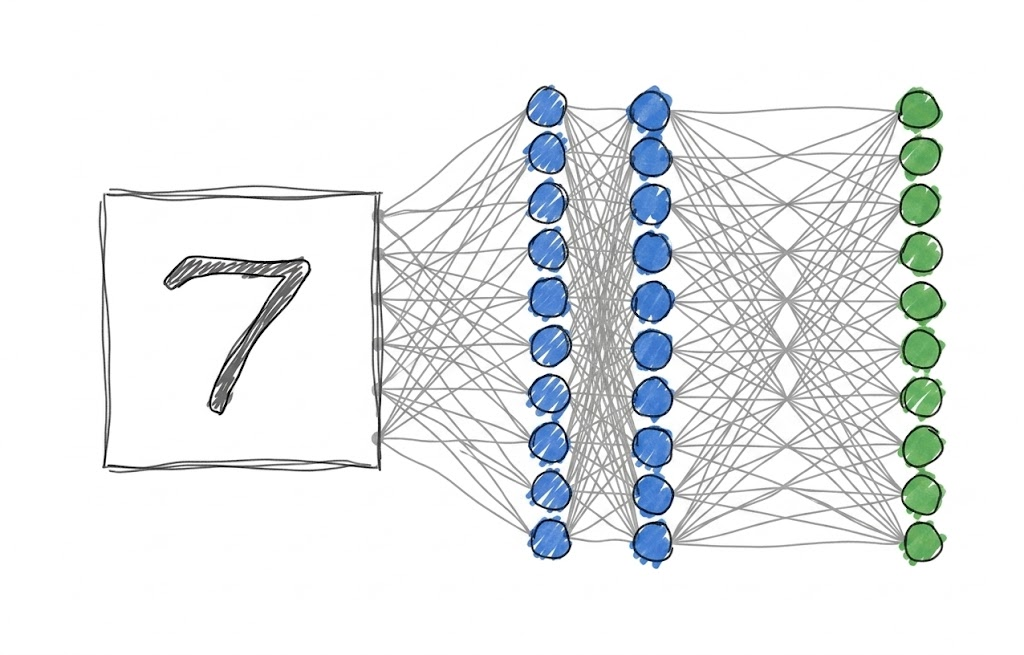
You would have seen something similar to the image above wherever you read about neural networks. This is how a basic neural network can be represented.
In our dataset, we have a lot of 28x28 pixel images, or basically, a lot of 784 pixel images. What our model in this example image does is:
- take an input vector with 784 elements
- the 10 circles, also called neurons or nodes do some math with the input vector and give an output vector with 10 elements.
- The output vector of this layer acts as an input vector for the second layer, and the second layer does some more math with it. This goes on and on for n-layers the neural network might have.
- The output of the last layer, which in this case is the third layer, is the output we desire. In this case, i element of the vector is the probability that the input represents i. For example, if the input image represents 7, then the output vector of the neural network must look something like: [0 0.04 0.02 0 0.04 0 0 0.9 0 0]
As you can clearly see, the probability of the 7 element is the highest, which suggests the input must be 7.
The math behind a neural network
At the first sight it might seem as if there is some magic math done by a neural network to accurately guess the user's input, but in fact the math is just a bunch of Matrix multiplications, with a sprinkle of Calculus. Each layer of neurons has associated matrices with it. Those are called Weights and Biases.
A neural network primarily performs 3 operations:
- Forward propagation: Take the input, pass it through all layers sequentially, and obtain the output.
- Backward propagation: Take the output and the expected output, pass gradients back through all layers starting from the end towards the beginning, and figure out what changes need to be made to the weights and biases.
- Updating weights and biases: After backward propagation, since our model knows what changes need to be made, update the weights and biases accordingly.
Notation
For discussing the math, we'll start with writing out the notation we will be using. Math becomes very very hard if we don't have any proper notation.
- : A matrix with m rows and n columns.
- : Weights of the layer
- : Biases of the layer
- : Input to the layer. is the original input to the model.
- : Pre-activation output of the layer.
- : Post-activation output of the layer. Also equals .
- : Total number of layers.
- : Predicted output (i.e., ), and
Yis the actual label.
Forward Propagation
For each layer i from 0 to L-1, two operations are performed:
Linear Combination:
Activation:
where g is the activation function. I won't go in depth on what an activation function is, but if you want to, you can refer to this article. In this model, as I mentioned earlier, we support ReLU and Softmax.
- ReLU: — used for hidden layers.
- Softmax: — used for the output layer, converts raw scores into probabilities that sum to 1.
Backward Propagation
This is the part that actually makes the network learn, and also the part that made me want to throw my laptop out the window the first time I implemented it.
The idea is to compute how much each weight and bias contributed to the error, so we know which direction to nudge them. We do this using the chain rule from Calculus.
We start from the output layer and work backwards. First, we need a loss function to measure how wrong we are. For a classification problem like MNIST, we use Cross-Entropy Loss:
Now, for the output layer using Softmax + Cross-Entropy, the gradient conveniently simplifies to:
Yeah, that's it. The math gods were kind here.
For every layer i going backwards from L to 1, we compute:
And then propagate the gradient to the previous layer:
where is the derivative of the activation function, and is elementwise multiplication. For ReLU, if , else .
Updating the Weights and Biases
Once we have the gradients, the actual update is the easy part — Gradient Descent:
where is the learning rate — a hyperparameter that controls how big a step we take. Too high and the model diverges. Too low and you'll die of old age before it converges.
Generalizing to n-layers
The beauty of this formulation is that it generalizes cleanly. Every layer has the same structure: weights, biases, an activation, and a backward pass. So instead of hardcoding a 2-layer network, we can just store layers in a list and loop over them — forward during inference, backward during training. That's literally the entire design philosophy of FlexNN.
Time to Code
Alright, enough math. Let's build the thing.
Prerequisites
FlexNN uses Eigen3 for matrix operations and CMake to build. On Ubuntu:
sudo apt install cmake libeigen3-dev
That's it.
Helper Functions
CSV Reading
MNIST data comes as a CSV where the first column is the label and the remaining 784 are pixel values. We skip the header and parse everything into Eigen matrices:
void FlexNN::readCSV_XY(const std::string &filename, Eigen::MatrixXd &X, Eigen::VectorXd &Y) {
std::ifstream file(filename);
std::vector<std::vector<double>> data;
std::string line;
size_t cols = 0;
if (std::getline(file, line)) { /* skip header */ }
while (std::getline(file, line)) {
std::stringstream ss(line);
std::string cell;
std::vector<double> row;
while (std::getline(ss, cell, ','))
row.push_back(std::stod(cell));
if (cols == 0) cols = row.size();
data.push_back(row);
}
size_t nRows = data.size(), nCols = cols;
X.resize(nRows, nCols - 1);
Y.resize(nRows);
for (size_t i = 0; i < nRows; ++i) {
Y(i) = data[i][0];
for (size_t j = 1; j < nCols; ++j)
X(i, j - 1) = data[i][j];
}
}
One-Hot Encoding
The network outputs 10 probabilities, but labels are just integers. We convert them into a one-hot matrix of shape (num_classes, num_samples):
Eigen::MatrixXd FlexNN::oneHotEncode(const Eigen::VectorXd &Y, int num_classes) {
Eigen::MatrixXd Y_onehot = Eigen::MatrixXd::Zero(num_classes, Y.size());
for (int i = 0; i < Y.size(); ++i) {
int label = static_cast<int>(Y(i));
if (label >= 0 && label < num_classes)
Y_onehot(label, i) = 1.0;
}
return Y_onehot;
}
Single Layer
Each Layer stores its weights W, biases b, and activation type. The forward pass returns a std::pair<Z, A> — both the pre-activation and post-activation outputs. We need both because backprop needs Z to compute the ReLU derivative.
Forward Pass
std::pair<Eigen::MatrixXd, Eigen::MatrixXd> FlexNN::Layer::forward(const Eigen::MatrixXd &input) {
Eigen::MatrixXd Z = (W * input).colwise() + b;
Eigen::MatrixXd A;
if (activationFunction == "relu") {
A = Z.unaryExpr([](double x) { return std::max(0.0, x); });
}
else if (activationFunction == "softmax") {
A = Z;
for (int i = 0; i < Z.cols(); ++i) {
Eigen::VectorXd col = Z.col(i);
Eigen::VectorXd expCol = (col.array() - col.maxCoeff()).exp(); // numerically stable
A.col(i) = expCol / expCol.sum();
}
}
else {
A = Z; // linear, no activation
}
return {Z, A};
}
The col.maxCoeff() subtraction before the exp is the numerically stable softmax trick — without it, large values in Z cause exp() to overflow. Small detail, big consequences.
Backward Pass
The layer's backward method takes the next layer's weights and dZ, and propagates the gradient back through this layer's activation:
Eigen::MatrixXd FlexNN::Layer::backward(const Eigen::MatrixXd &nextW,
const Eigen::MatrixXd &nextdZ,
const Eigen::MatrixXd &currZ) {
if (activationFunction == "relu") {
return (nextW.transpose() * nextdZ).array()
* (currZ.array() > 0.0).cast<double>();
}
// linear fallback
return nextW.transpose() * nextdZ;
}
Notice there's no softmax case here — and that's intentional. The softmax + cross-entropy gradient at the output layer simplifies to just A - Y, so it's handled directly in the network's backward pass, not here.
Neural Network
With layers working, NeuralNetwork just chains them.
Forward Pass
We store every intermediate Z and A in an outputs vector — we'll need all of them during backprop:
std::vector<Eigen::MatrixXd> FlexNN::NeuralNetwork::forward(const Eigen::MatrixXd &input) {
std::vector<Eigen::MatrixXd> outputs;
outputs.push_back(input); // index 0: original input
for (size_t i = 0; i < layers.size(); ++i) {
auto [Z, A] = layers[i].forward(outputs.back());
outputs.push_back(Z); // Z at index 2i+1
outputs.push_back(A); // A at index 2i+2
}
return outputs;
}
After this, outputs looks like: [X, Z₀, A₀, Z₁, A₁, ...]. The indexing matters — backprop walks this in reverse.
Backward Pass
The output layer gradient is A_last - Y_onehot. From there we walk backwards, calling each layer's backward() to get dZ for the previous layer, and accumulating dW and db along the way:
std::vector<Eigen::MatrixXd> FlexNN::NeuralNetwork::backward(
const std::vector<Eigen::MatrixXd> &outputs, const Eigen::MatrixXd &target) {
std::vector<Eigen::MatrixXd> gradients;
std::vector<Eigen::MatrixXd> dZs;
int m = outputs.back().cols();
// Output layer: softmax + cross-entropy gradient = A - Y
Eigen::MatrixXd dZ = outputs.back() - target;
dZs.push_back(dZ);
gradients.push_back(dZ.rowwise().mean()); // db
gradients.push_back(dZ * outputs[outputs.size() - 3].transpose() / m); // dW
// Hidden layers
for (int i = layers.size() - 2; i >= 0; --i) {
dZ = layers[i].backward(layers[i + 1].getWeights(), dZs.back(), outputs[2 * i + 1]);
dZs.push_back(dZ);
gradients.push_back(dZ.rowwise().mean()); // db
gradients.push_back(dZ * outputs[2 * i].transpose() / m); // dW
}
std::reverse(gradients.begin(), gradients.end()); // align with layer order
return gradients;
}
Updating Weights
Gradients come back interleaved as [dW₀, db₀, dW₁, db₁, ...]:
void FlexNN::NeuralNetwork::updateWeights(
const std::vector<Eigen::MatrixXd> &gradients, double learningRate) {
for (int i = 0; i < layers.size(); ++i) {
Eigen::MatrixXd dW = gradients[2 * i];
Eigen::VectorXd db = gradients[2 * i + 1];
layers[i].updateWeights(dW, db, learningRate);
}
}
Training
Putting it all together — one-hot encode the labels, then loop:
void FlexNN::NeuralNetwork::train(const Eigen::MatrixXd &input, const Eigen::MatrixXd &target, double learningRate, int epochs) {
Eigen::MatrixXd Y_onehot = FlexNN::oneHotEncode(target, target.maxCoeff() + 1);
for (int epoch = 0; epoch < epochs; ++epoch) {
auto outputs = forward(input);
auto gradients = backward(outputs, Y_onehot);
updateWeights(gradients, learningRate);
if ((epoch + 1) % 10 == 0)
std::cout << "Epoch " << epoch + 1 << "/" << epochs
<< ": Accuracy = " << this->accuracy(input, target) << std::endl;
}
}
Evaluating Accuracy
double FlexNN::NeuralNetwork::accuracy(const Eigen::MatrixXd &X, const Eigen::MatrixXd &Y) {
Eigen::MatrixXd predictions = this->predict(X);
int correct = 0;
for (int i = 0; i < predictions.cols(); ++i) {
int predictedClass;
predictions.col(i).maxCoeff(&predictedClass);
if (predictedClass == static_cast<int>(Y(i))) correct++;
}
return static_cast<double>(correct) / predictions.cols();
}
And as a fun bonus — main.cpp has a little interactive loop where you enter an index and it prints the digit as ASCII art using #, *, ., and spaces based on pixel intensity.
Analysis
With a 784 → 64 ReLU → 10 Softmax architecture, learning rate of 0.5, trained for 300 epochs on a 90/10 train-test split:
- Training accuracy: ~95–96%
- Test accuracy: ~93–94%
- Training time: A few minutes on CPU.
Not bad for zero ML frameworks. PyTorch would hit 99% in 10 lines — but you'd also understand approximately nothing about why it works. That was the whole point.
How to Refine
Vectorization
Eigen already uses SIMD internally — but only if you compile with the right flags. If your CMakeLists.txt has:
target_compile_options(FlexNN PRIVATE -O3 -march=native)
Free speedup, zero code changes.
Multithreading with OpenMP
The README mentions OpenMP support. Eigen can be told to use it internally, and you can parallelize the training loop across batches with #pragma omp parallel for. The infrastructure is already there — just needs to be wired in properly.
Mini-batch Gradient Descent
Right now training runs on the full dataset every epoch (batch gradient descent). Mini-batches would converge faster and generalize better. Shouldn't be a huge change given how splitXY is already written.
What Can Be Improved
Plenty:
- More optimizers — Adam, RMSProp, SGD with momentum. Plain gradient descent works but it's the slow lane.
- More activations — Sigmoid, Tanh, Leaky ReLU. The architecture already supports plugging them in.
- Model save/load — Right now you retrain from scratch every run. Serialize the weights to disk and this becomes actually usable.
- Convolutional layers — For real image tasks, dense layers are not the move. But that's a whole different beast.
- GPU support — Not happening from me anytime soon. Swap Eigen for cuBLAS if you're feeling adventurous.
The code is on GitHub if you want to poke around. And if you find a bug — feel free to open an issue. I might fix it. Eventually. Probably after exams.
That's where FlexNN stands for now. The more I look at it though, the more I think there's something worth pursuing here — a lightweight, dependency-minimal inference engine in C++ is not far from something you could run on an embedded system. No Python runtime, no TFLite overhead. A proper lightweight alternative to TensorFlow Lite for edge applications. That's the direction I'm thinking of taking this next.
If that sounds interesting, do reach out!
More stuff coming soon. 👀